Connascence is a software metric for measuring the impact of coupling in your code base. The rules and language it provides allow you to make more informed decisions about how to structure or refactor your code. Two components are considered connascent if a change to one would require a change to the other. The stronger the connascence between two components, the more change is required.
How is it measured?
Connascence is measured over three axes, each having an impact on the overall severity.
- Strength. Stronger connascence is harder to identify and refactor. Strength is determined by the rule.
- Degree. How many entities are involved. Is it one, or is it thousands?
- Locality. How close the entities are together. Stronger connascence is less of a problem if entities are close together.
Improving your code on any of these axes will make it easier to work with in the future. In some cases I’ve included a little bit of advice on how I’d approach it.
Now that we’ve established what it is, and how it’s measured, let’s have a look at the rules.
Static vs Dynamic Connascences
There are two types of connascence. Static and dynamic.
Static connascence can be found by visually studying the code and with static code analysis.
Dynamic connascence can only be discovered by running your code. These are considered stronger because they are harder to find and fix.
Ordered by Strength
The higher in this list the better.
- Connascence of Name
- Connascence of Type
- Connascence of Meaning
- Connascence of Position
- Connascence of Algorithm
- Connascence of Execution
- Connascence of Timing
- Connascence of Value
- Connascence of Identity
Static Connascences
Connascence of Name
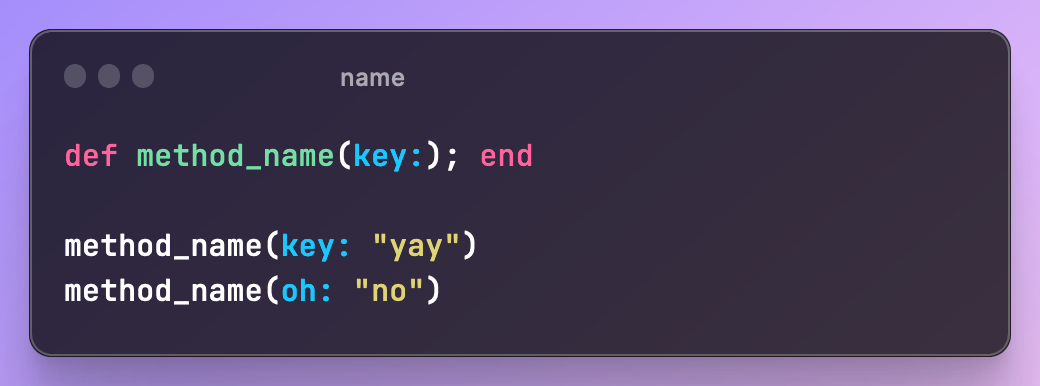
When multiple elements must agree to the name of an entity, e.g. class name, method name. When a method name changes, the callers of that method need to change their reference to the match new name.
It’s almost impossible to avoid connascence of name, but it’s also very easy to refactor. Many languages have tools to automate the process of renaming methods, variables, and classes.
Connascence of Type
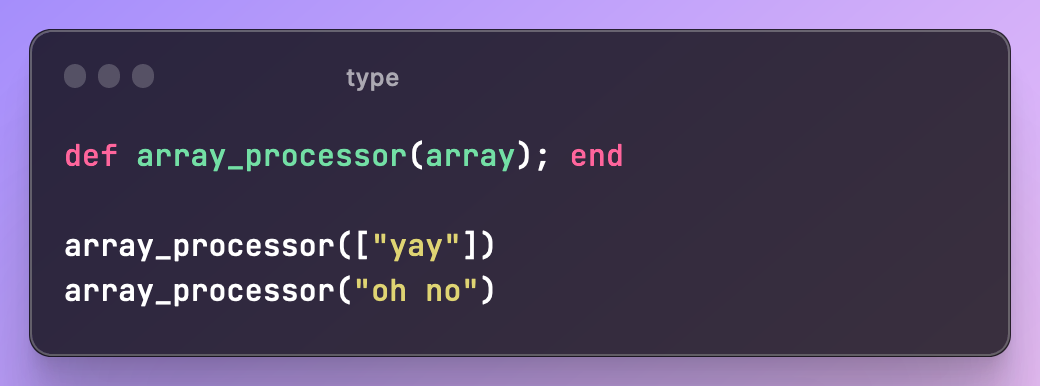
When multiple components must agree on the type of an entity. A statically typed language will catch these with the compiler, but they can be harder to catch with a dynamically typed language. If your test data is not set up the same as the data used when your code is running, you may not catch these issues right away.
Managing Connascence of Type
You can reduce the impact of connascence of type in dynamically typed languages like Ruby by using methods like respond_to?.
Though it’s not as strict as type checking, it makes it clear to the caller what methods the given variable is expected to have.
Using structs instead of hashes is another way that you can add a bit of structure to your code, and make it easier for other developers to understand what they can expect when they are working with a variable.
Connascence of Meaning
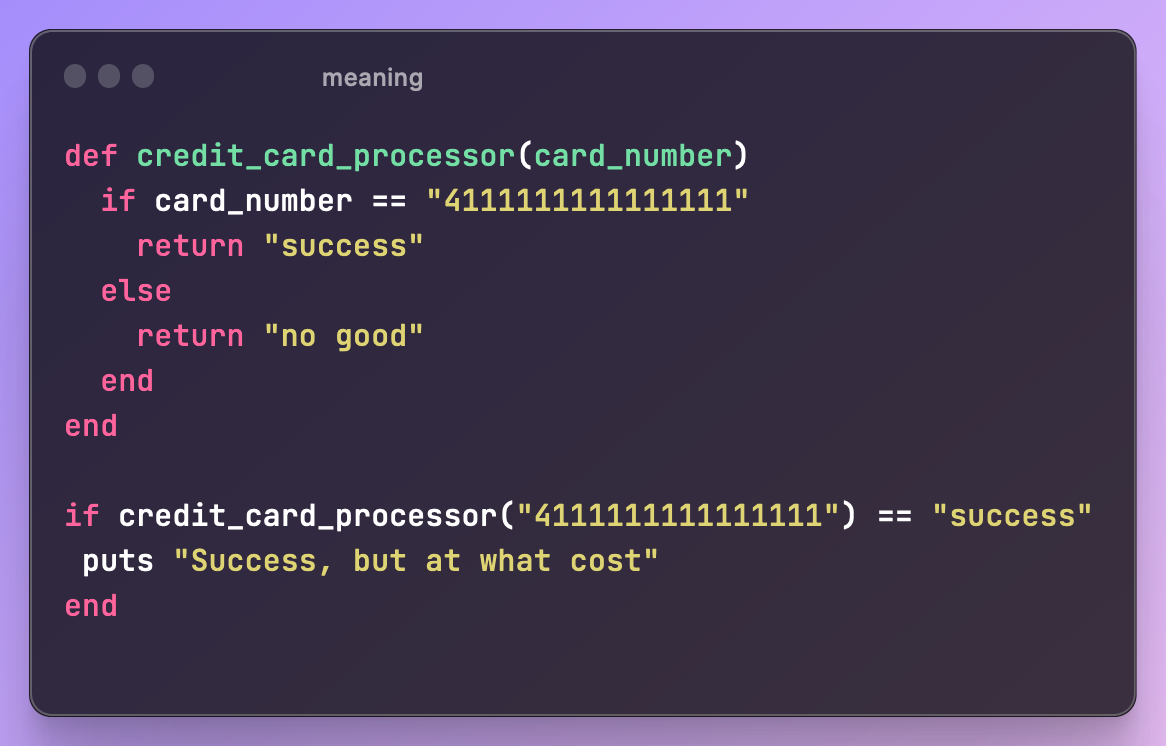
When multiple entities must agree on the meaning of particular values for them to function correctly, e.g. if you have decided that a test credit card has the format 4111 1111 1111 1111. If important values like these aren’t stored somewhere that they can be referenced, there is a risk that logic which depends on them gets out of sync.
Connascence of meaning often appears as “magic strings”. Magic strings are important values which aren’t stored in variables. Without the context of a variable, it can sometimes make it difficult to understand the purpose of the value, and may require the developer to read the surrounding code to understand what the value is for, and why it’s important.
Managing Connascence of Meaning
Any reference value should be stored in a constant, even if it’s only used once. A named constant is useful because it provides a central source of truth, allows you to use the name to explain its purpose, and creates a logic place to store related comments.
If creating a constant doesn’t make sense for your given scenario, the next best option is to create a method to wrap around interactions with the value. Similar to the constant it provides a central place for documentation, and reduces the moving parts when a change does need to be made.
Connascence of Position

When multiple entities have to agree on the order of values. Such as a method taking positional parameters. These can be particularly easy to miss when all parameters are the same type.
This concept can also apply to data structures which require information to be in a specific order, e.g. a tuple or array.
Managing Connascence of Position
Use keyword parameters whenever practical. They are more verbose, but adjusting from positional to keyword parameters changes it from connascence of position to connascence of name, which is less likely to cause unexpected side-effects when changed.
Connascence of Algorithm
When two entities must manipulate data in the same way. For example, when two entities are communicating with encryption they need to be using the same algorithm.
Connascence of algorithm also includes the way that data is validated. If your data is validated differently by different entities, you may find that one entity allows data into your system that other parts consider invalid. Issues like this can be particularly annoying to fix because it may involve updating a large amount of invalid data which is already stored in your system.
Dynamic Connascences
Connascence of Execution
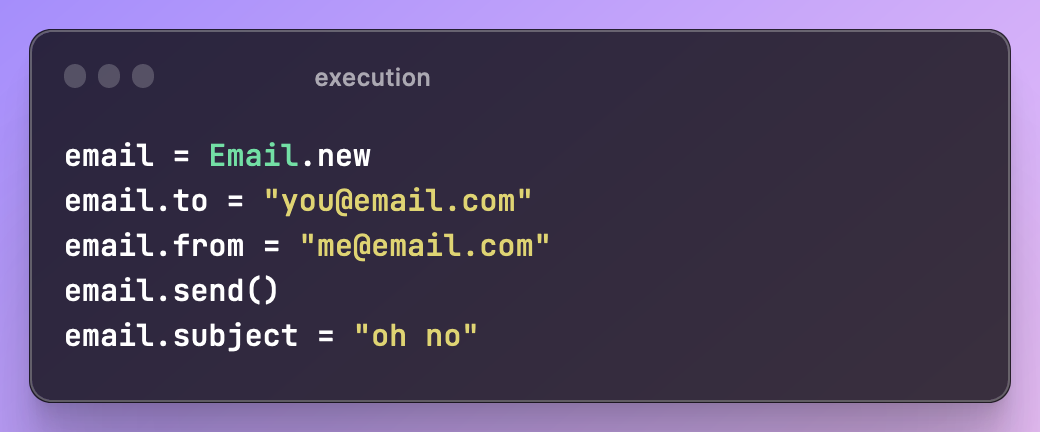
When the order of execution between multiple components is important. This includes state machines which only allow certain operations for certain states.
Managing Connascence of Execution
Keep logic which depends on the order of execution as local as possible. If it’s not possible to keep logic local then I would recommend putting checks into your code to see if expected operations have happened before proceeding, i.e. defensive programming. Adding checks like this won’t prevent these errors from happening, but they will make them loud and easier to understand.
Connascence of Timing
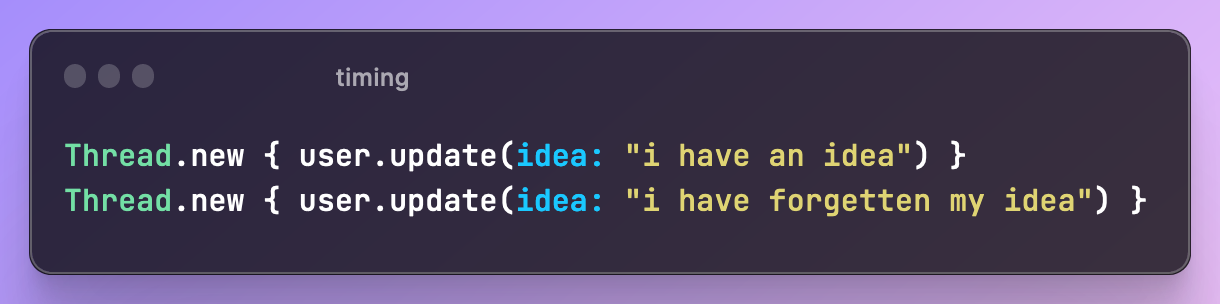
When the timing of execution matters between multiple components is important. You will commonly hear these referred to as race conditions.
Managing Connascence of Timing
Locks can be used to ensure that a resource is only being worked on by one entity at a time, but won’t ensure that they are done in a particular order.
In a distributed system you can reduce the impact of timing related issues by allowing queues to retry when information is missing. They may fail if they depend on another operating being completed, but on retry they may work once that information has become available.
Designing your system to be self-healing will allow it to recover when information is missing, either by requesting it, or retrying until the information is available.
Connascence of Value
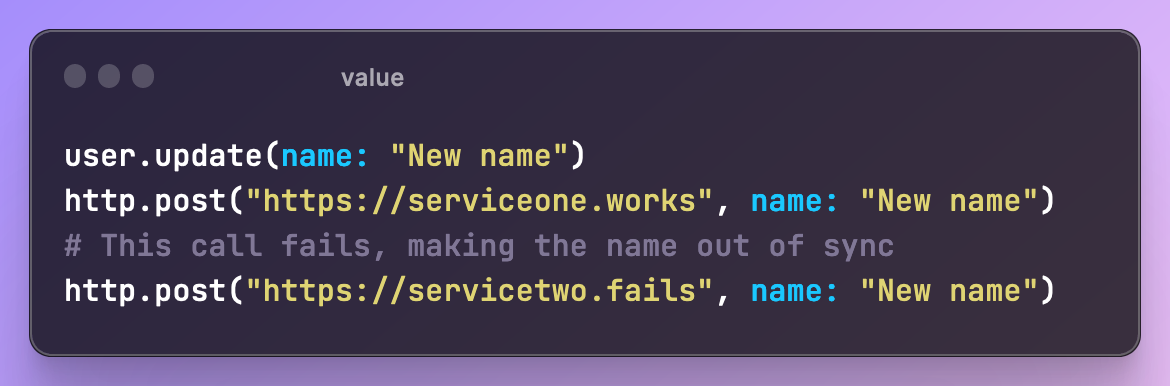
When multiple values must change together.
This is a major problem when you want to create a transaction over distributed systems. In these scenarios you want to update all services or none, however separate databases mean that rolling back an operation needs to be done manually in code.
Managing Connascence of Value
Transactions over multiple distributed services are a pain, so it’s best to avoid them as much as possible. If this is happening often within your system, it could be an indication that the responsibilities of these systems need to be adjusted.
However, there are often times that there is no way of avoiding a distributed transaction. In those cases there are a few methods I’ve used to mitigate these types of issues.
Queues can be used if you don’t mind eventual consistency. Having a dead letter queue to catch the messages that fail to process successfully will allow you to ensure that no message is left unprocessed.
You can make your endpoints idempotent. There are many “good enough” ways of making code idempotent. For example, using find_or_create_by instead of create. Though it’s not perfect, it allows an API to be called multiple times without needing much custom logic.
When interacting with remote services, perform the actions that are most likely to fail first. This is pretty flimsy, but it can be better than nothing if you are in a hurry.
Connascence of Identity
When multiple components must reference the same instance of an entity. Imagine separate entities thinking that they were working with the same instance of an object, when in reality they had different copies.
If you had entities putting messages onto a queue and an entity processing those messages, you would run into issues if they weren’t referencing the queues that they thought they were.
Managing Connascence of Identity
Singleton pattern can be used to avoid connascence of identity, because it ensures there will only be one instance of a given entity. This guarantees that the referenced instances will match, but does prevent you from having more than one instance.
Resources
Unsurprisingly connascence.io is a great resource on the topic of connascence. Their list of resources is vast.
These are some other resources I found useful as I wrote this post.
- https://programhappy.net/2020/09/19/fixing-dynamic-connascence/
- https://thoughtbot.com/blog/connascence-as-a-vocabulary-to-discuss-coupling
- https://khalilstemmler.com/wiki/coupling-cohesion-connascence/
Goodbye
Thanks for coming. I feel like this is a post I’ll come back and edit, so don’t get too attached. If you have any feedback you are welcome to send it to the email found on my about page.